Capítulo 3 Alternativa geométrica
3.1 Funciones de Distancia en Problemas de Localización
- Distancia basada en norma de vectores
- Distancia de norma 2 o distancia Manhatam
- Distancia Euclídea
- Distancia con otras normas aplicada almacenamiento y almacenamiento con gradiente de temperatura o problemas de Material Handling (salas de cirugía).
- Distancia Matricial y casos de bloqueos (muros, zonas anegadas, etc).
- Varianza de las distancias con distintas normas.
- Curva de Hilbert.
- Revisión bibliográficas de métodos de antecesores de facility location.
- Ejercitación del capítulo
3.2 Distancia basada en norma de vectores
La distancia es una descripción numérica de la distancia entre los objetos en un momento dado. En física o en la discusión cotidiana, la distancia puede referirse a una longitud física, un período de tiempo o se estima en base a otros criterios. Al tomar decisiones sobre la ubicación, la distribución de las distancias de viaje entre los destinatarios del servicio (clientes) es un tema importante. La mayoría de los estudios de ubicación clásicos se centran en la minimización de la distancia media (o total) (el concepto de mediana) o la minimización de la distancia máxima (el concepto de centro) a las instalaciones de servicio. (Ogryczak 2000) En estos estudios, el modelado de ubicación se divide en cuatro categorías amplias:
Modelos analíticos. Estos modelos se basan en una gran cantidad de supuestos simplificadores, como el costo fijo de ubicación de la instalación. Las distancias de viaje siguen la métrica de Manhattan.
Modelos continuos. Estos modelos son los modelos de ubicación más antiguos, se ocupan de representaciones geométricas de la realidad y se basan en la continuidad del área de ubicación. El modelo clásico en esta área es el problema de Weber. Las distancias en el problema de Weber a menudo se toman como distancias en línea recta o euclidianas, pero aquí se pueden usar casi todos los tipos de funciones de distancia (Jiang y Xu 2006; Hamacher y Nickel 1998).
En el estudio de la teoría de la ubicación continua, generalmente se asume que los clientes pueden ser tratados como puntos en el espacio. Esta suposición es válida cuando las dimensiones de los clientes son pequeñas en relación con las distancias entre la nueva instalación y los clientes. Sin embargo, no siempre es así. A veces, no debemos ignorar las dimensiones de los clientes. Algunos investigadores han tratado a los clientes como regiones de demanda que representan la demanda de una región.
Jiang y Xu (2006) discutieron que algunos investigadores como Brimberg y Wesolowsky en 1997, 2000 y 2002 y Nickel et al. en 2003 usó la distancia entre la instalación y el punto más cercano de una región de demanda; y en los demás, la distancia entre la instalación y una región de demanda puede calcularse como alguna forma de distancia de viaje esperada o promedio.
Modelos de red. Los modelos de red se componen de enlaces y nodos. Los modelos de 1 mediana absoluta, 2 centros no ponderados y mediana L de criterios q en un árbol son algunos de los modelos bien conocidos en esta área. Las distancias se miden con respecto al camino más corto.
Modelos discretos. En estos modelos, hay un conjunto discreto de ubicaciones candidatas. Los modelos discretos de cobertura y ubicación de instalaciones no capacitadas, de media N discreta son algunos de los modelos bien conocidos en esta área. Al igual que las distancias en los modelos continuos, aquí se pueden utilizar todo tipo de funciones de distancia, pero a veces se pueden especificar de forma exógena (Hamacher y Nickel 1998; Fouard y Malandain 2005).
Las distancias y las normas suelen definirse en el espacio finito \(E^n\) y toman valores reales. En geometría discreta, sin embargo, a veces necesitamos tener distancias discretas definidas en \(Z\) n con sus valores en \(Z\). Dado que \(Z\) n no es un espacio vectorial, la noción de distancias y normas tuvo que extenderse.
3.3 Especificación de Norma y Distancia
Asumamos la existencia de dos puntos \(X = (x_1,y_1)\) y \(Y = (x_2,y_2)\). Luego la distancia entre ellos se puede expresar matemáticamente como \(d(X,Y)\). Según el tipo de problema que abordemos esta distancia entre \(X\) e \(Y\) respetará algunas características que le impondremos para que represente nuestro real inconveniente en el problema que abordamos. No será lo mismo el problema de distancia en una autopista, que en un centro urbano con tránsito bloqueado, o en un piso de manufactura donde los robots cruzan con peatones que no deben embestir.
En cualquier teorema o ágeblra grado para lidiar con estos problemas definimos algunas cosas repetitivias pero básicas.
Condición de positividad \[ d(X,Y) \ge 0 , \forall X,Y \] Definición de cero \[ d(X,Y) = 0 \Leftrightarrow X=Y , \forall X,Y \] Definición de simetría \[ d(X,Y) = d(Y,X) \forall X,Y \] Inequidad Triangular \[ d(X,Y) \leq d(X,R) + d(R,Y) \forall X,Y \]
3.4 Función de Distancia
La función de de distancia entre los puntos \(X = (x_1, x_2, ... X_n)\) y \(Y = (y_1, y_2, ... y_n)\) es llamada \(d_{K,p}\) o distancia Minkowski de orden \(p\), que definiremos como.
\[ d_{K,p} (X.Y) = (\sum_{i=1}^{n} (|x_i - y_i|)^p )^{(\frac{1}{p})}\]
Los parámetros \(k1\) y \(k2\) de la norma \(d_{k,p}\) pueden verse como pesos desiguales o irregularidades de distancia no simétricas a lo largo de las direcciones de los ejes. Un trabajo empírico mostró que la precisión de las estimaciones de distancia en este tipo de norma es mejor que la ponderada d_{k; p} (Uster y Love 2003) En la situación en la ecuacion anterior, podemos definir algunas funciones de distancia famosas como:
SI \(p =1\) se pueden obtener las distancias de 1 norma, rectilínea, tambien llamada Distancia Manhattan o en ángulo recto: Es la más utilizada para logística de última milla.
Las distancias rectilíneas se aplican cuando se permite viajar solo en dos direcciones perpendiculares, como las arterias Norte-Sur y Este-Oeste. Esta distancia también es popular entre los investigadores porque el análisis suele ser más simple que emplear otras métricas (Drezner y Wesolowsky 2001).
La distancia rectilínea también se denomina distancias de norma de taxi; porque es la distancia que recorrería un automóvil en una disposición de la ciudad en bloques cuadrados (si no hay calles de un solo sentido).
Si \(p = 2\) la norma es 2 conocida como noram Euclídea. Que nos dá la clásica formulación de distancia que generalmente asumimos como la única distancia que existe.
\[ d_{K,p} (X.Y) = \sqrt[]{\sum_{i=1}^{n} |x_i - y_i|^2 } \]
Si \(p = \infty\) se obtiene la norma de Chebishev que se utiliza en fenómenos no estacionarios como calculo de distancias en gases que se exánden, derrames que fluyen, desconcentración de peatones en partidos de fútbol, etc.
\[ d_\infty (X,Y)= lim_{p \rightarrow\infty} (\sum_{i=1}^{\infty} |x_i-y_i|^p)^{\frac{1}{p}} = max (|x_1-y_1| , ... , |x_n,y_n|)\]
3.5 Distancia de pasillo
Como se mencionó anteriormente, la función de distancia rectilínea o euclidiana son los métodos más comunes utilizados en los modelos, sin embargo, estas medidas de distancia no son realistas para algunas aplicaciones, como la manipulación de materiales en plantas. La figura siguiente muestra los pasillos de una planta. Las distancias de recorrido de los pasillos entre departamentos se pueden encontrar formulando y encontrando la ruta más corta en un problema de red y se pueden especificar para proporcionar la distancia necesaria entre los recursos. Esto permite evaluar la distancia real de recorrido del pasillo para cada diseño que se genera durante el proceso de búsqueda. (Norman et al. 2001).
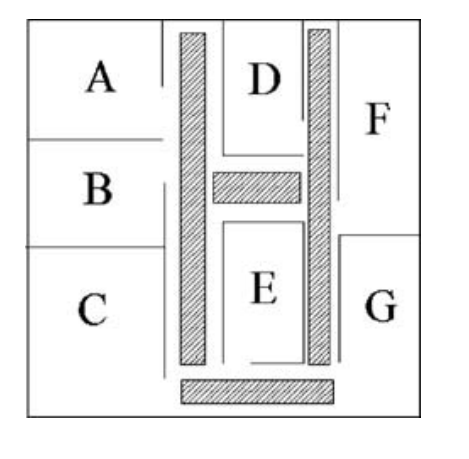 Para calcular la distancia del pasillo, se deben considerar las estrategias de los sistemas de manipulación. “La ruta de un recolector sigue el tráfico selectivo en un solo sentido, ya que atraviesa una longitud completa del pasillo que contiene los artículos que se van a recolectar y no se le permite dar la vuelta o retroceder, pero termina en el lado opuesto del pasillo después de recolectar
Los artículos. La ruta óptima en esta estrategia es organizar los artículos dentro del lote de manera que los artículos que se encuentran en el pasillo más cercano a la estación de entrada / salida se recojan primero y luego el siguiente pasillo más cercano. Cuando se selecciona el último artículo, el recolector volverá a la estación de E / S”. Chew y Tang (1999) es un ejemplo de estas estrategias.
Para calcular la distancia del pasillo, se deben considerar las estrategias de los sistemas de manipulación. “La ruta de un recolector sigue el tráfico selectivo en un solo sentido, ya que atraviesa una longitud completa del pasillo que contiene los artículos que se van a recolectar y no se le permite dar la vuelta o retroceder, pero termina en el lado opuesto del pasillo después de recolectar
Los artículos. La ruta óptima en esta estrategia es organizar los artículos dentro del lote de manera que los artículos que se encuentran en el pasillo más cercano a la estación de entrada / salida se recojan primero y luego el siguiente pasillo más cercano. Cuando se selecciona el último artículo, el recolector volverá a la estación de E / S”. Chew y Tang (1999) es un ejemplo de estas estrategias.
3.6 Matriz de distancia
Yu y Sarker (2003) indicaron que Sarker en 1989 y Sarker et al. en 1994 y 1998 desarrollaron una serie de propiedades amebianas de una matriz de instancias para ubicaciones lineales igualmente espaciadas para generar diferentes asignaciones de máquinas a ubicaciones que minimizan los flujos unidireccionales y / o bidireccionales totales. La forma de una matriz de distancias puede variar a medida que cambia su asignación de ubicación correspondiente.
\[d_{XY}=\mid{X-Y}\mid = \left\lbrace \begin{array}{c} X-Y \space if \space 1\le Y < X \le L \\ Y-X \space if \space 1\le X < Y \le L \\ 0 \space if \space 1\le Y = X \le L \end{array}\right\rbrace\]
Cada distancia puede ser descompuesta en dos diferentes direcciones que se definen como:
- Backward: \(d^B\) es la matriz de sitancias de retrocesos \(d_{XY}^B\) Tal que:
\[d_{XY}^B = \left\lbrace \begin{array}{c} X-Y \space if \space 1\le Y < X \le L \\ 0 \space \space \space else \end{array} \right \rbrace\] -Fordward: \(d^F\) es la matrix de distancia de avance, con los elementos \(D_{XY}^F\) Y (Yu and Sarker 2003)
\[d_{XY}^B = \left\lbrace \begin{array}{c} Y-X \space if \space 1\le X < Y \le L \\ 0 \space \space \space else \end{array} \right \rbrace\] ## Distancia de cuadras
Dearing y col. (2005) discutieron que las distancias entre bloques son un caso especial de distancias normales que fueron introducidas a los modelos de ubicación por Witzgall et al. en 1964 y Ward y Wendell en 1985. Las distancias en bloque se utilizan para modelar la distancia de viaje en aplicaciones donde las direcciones de viaje están restringidas a las direcciones fundamentales. También tiene un amplio uso en problemas de barreras. También pueden verse como una generalización de distancias en orientaciones fijas, tal como lo introdujeron Widmayer et al. En 1987. (Dearing et al.2005) donde se supone que todas las direcciones fundamentales tienen una unidad de longitud, es decir
\[ ||a_K|| = 1 \quad \forall \quad k=1,2,......,2n,\] donde \(||a_K||\) es la norma euclidea de \(a_k\)
La distancia de bloque entre los puntos, \(X_1\) y \(X_2\) con respecto a un conjunto dado de direcciones fundamentales \(a_1, a_2; ....; a_{2n}\) se denota por \(d_p(X_1; X_2)\) y se define como
\[d_p(X_1; X_2) = \alpha_{12} + \beta_{12}\];
donde \(\alpha_{12}\) y \(\beta{12}\) son escalares no negativos teles que (Dearing et al. 2005)
\[ X_2 - X_1 = \alpha_{12} + \beta_{12}\alpha{k+1} \quad \forall \quad k= 1,2,...2n\]
3.7 Curva de Hilbert
Cantor fue el primer investigador en mapear el intervalo [0, 1] en el cuadrado [0, 1] 2. Más tarde, se presentó la primera curva de llenado de espacio, la curva de Peano, para construir una curva que pasa por cada entrada de una región bidimensional. Posteriormente, se presentaron varias curvas de llenado de espacio diferentes y la curva de Hilbert es la más conocida (Chung et al. 2007).
La curva de Hilbert es una curva continua que pasa por cada punto del espacio exactamente una vez. Permite a uno mapear continuamente una imagen en una línea y es una excelente imagen 2D para mapear líneas. La posición de cada píxel en la línea mapeada se denomina orden de Hilbert de ese píxel (Song y Roussopoulos 2002).
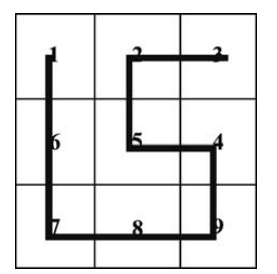 Este tipo de curva pone de manifiesto que en muchas ocasiones las distancias no son la única métrica relevante, sino que otros problemas a optimizar como el ruteo pueden condiciones la distancia que deberemos asumir.
Este tipo de curva pone de manifiesto que en muchas ocasiones las distancias no son la única métrica relevante, sino que otros problemas a optimizar como el ruteo pueden condiciones la distancia que deberemos asumir.
3.8 Uso de grafos
En algunas oportunidades, dentro de los problemas que se pretende resolver es necesario apelar a una representación gráfica de los mismos y utilizar técnicas de las que se utilizan en problemas de facility location. Por ejemplo técnicas de innovación como Triz o Scamper recurren a hacer mapeo de ideas y en ellas las distancias entre los nodos (equivalentes a ciudades) se asocian con la derivada del conocimiento respecto del tiempo $ { t} = I $. En particular en estos tipo s de problemas si se pretende resolver la ecuación diferencial que expondremos como
\[ \int_{k_t}^{k_T} \partial k = \int_{t=0}^{T} I \quad \partial t\] Si consideras que I (inteligencia) es constante con el tiempo la puedes sacar fuera de la integral y tu problema estará resuelto.
Pero habitualmente la inteligencia es función del tiempo y este tipo de problema es lo que se conoce como un problema con memoroia o problema dinámico. Es posible predecir su estado futuro, pero todo depende del estado inediatamente anterior.
Una buena forma de tratar las distancias que aparecen entre los nodos, que no son distancias sino flujos de conocimiento, es mediante el mapeo de grafos y la técnica de las cadena de Markov.
Recorreremos brevemente la forma de ver como este “tipo de distancias” afecta al comportamiento de todo el sistema. Adicionalmente introduciremos algunas de las herramientas con las que trabajaremos el resto del curso.
Recomiendo ver en este y otros problemas este material:
Si notas que el enlace está muy lento o que nuestro ancho de banda está congestionado puedes acceder a la versión que está cacheada en la biblioteca de la universidad.
3.9 Cadenas de Markov en R
3.10 Proceso Estocásticos
Instalación del Paquete
Para instalar un paquete en R se utiliza el comando “install.packages()”, para mayor información se digita en el compilador el código:
help(“install.packages”)
De esa forma se accede a la documentacion de dicha funcion almacenada en el CRAN. Para analizar cadenas de markov finitas utilizaremos el paquete “markovchain” version 0.6.9.11 publicado por: Giorgio Alfredo Spedicato, Tae Seung Kang y otros. En el siguiente chunk se presenta los comandos necesarios para instalar y cargar al sistema el paquete. Note que la primera linea de código tiene el simbolo “#” que es utilizado para comentar.
# install.packages("markovchain")library(markovchain)## Package: markovchain
## Version: 0.8.6
## Date: 2021-05-17
## BugReport: https://github.com/spedygiorgio/markovchain/issuesEl comando “library” carga al sistema el paquete
3.11 Introducción a markovchain
Para conocer los detalles, especificaciones o ejemplos de la libreria basta con digitar el siguiente comando, que automaticamente los redireccionará a su propia documentación.
help("markovchain")Esta libreria pretende proveer objetos para realizar analisis estadísticos de cadenas de markov a tiempos discretos. Asumamos que tenemos una cadena de markov X={X1,X2,…} definida en el espacio de estados S={a,b,c} y cuya matriz de transición es:
\[P=\lbrace 0,0.5,0.5 , 0.5,0,0.5,0.5,0.50 \rbrace\]
Dicha cadena podemos crearla en R, de la siguiente forma:
Crear la matriz de transicion P:
P = matrix(c(0,0.5,0.5,.5,0,.5,.5,.5,0),nrow = 3,byrow = TRUE)
P## [,1] [,2] [,3]
## [1,] 0.0 0.5 0.5
## [2,] 0.5 0.0 0.5
## [3,] 0.5 0.5 0.0El argumento “nrows” de la funcion matrix es para declarar el numero de filas que deseamos que nuestra matriz P posea, y el argumento “byrows” es para que almacene los elementos de la matriz almacenados en c(), fila por fila.
Crear la matriz de transición creamos el objeto “markovchain” de la siguiente forma: mc = new(“markovchain”,transitionMatrix=P,states=c(“a”,“b”,“c”),name=“Cadena 1”) Una revisión previa al análisis de nuestra cadena se puede realizar mediante los comandos “str()” y “summary”, que devuelven la estructura del objeto y el resumen general de los resultados respectivamente. Para mayor informacion revisar los comandos mediante la función help().
mc = new("markovchain",transitionMatrix=P,states=c("a","b","c"),name="Cadena 1") 3.12 La estructura del objeto mc es:
library(markovchain)
str(mc)## Formal class 'markovchain' [package "markovchain"] with 4 slots
## ..@ states : chr [1:3] "a" "b" "c"
## ..@ byrow : logi TRUE
## ..@ transitionMatrix: num [1:3, 1:3] 0 0.5 0.5 0.5 0 0.5 0.5 0.5 0
## .. ..- attr(*, "dimnames")=List of 2
## .. .. ..$ : chr [1:3] "a" "b" "c"
## .. .. ..$ : chr [1:3] "a" "b" "c"
## ..@ name : chr "Cadena 1"mc es un objeto de tippo markovchain, que representa una lista con los argumentos provistos declarados en el constructor.
El resumen de la cadena es:
summary(mc)
summary(mc)## Cadena 1 Markov chain that is composed by:
## Closed classes:
## a b c
## Recurrent classes:
## {a,b,c}
## Transient classes:
## NONE
## The Markov chain is irreducible
## The absorbing states are: NONEPara visualizar el diagrama de transición de la cadena lo realizamos con la función plot(mc)
plot(mc)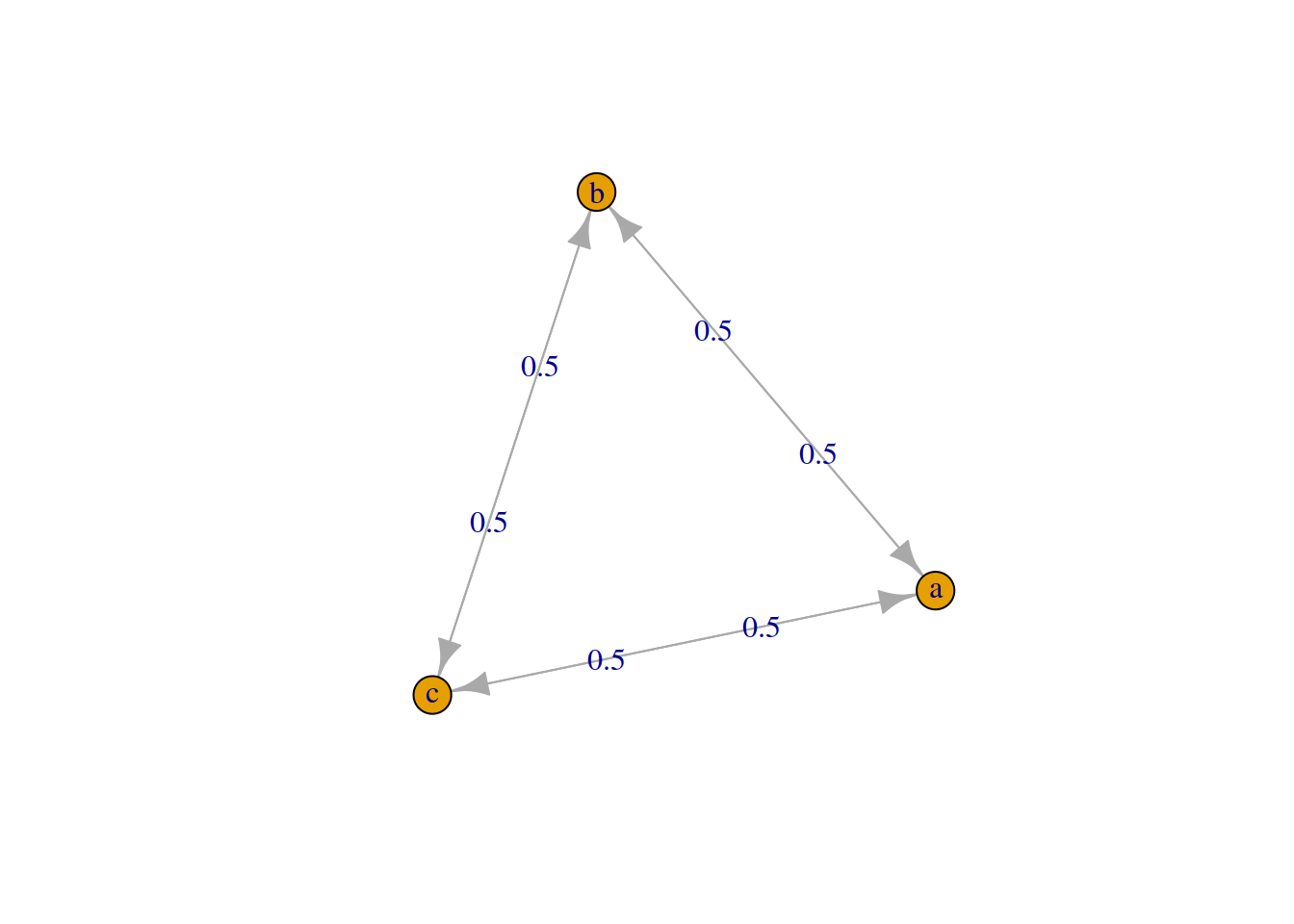
Otras funciones importantes son:
absorbingStates(): Identifica los estados Absorbentes
transientStates(): Identifica los estados Transitorios
recurrentClasses(): Identifica las clases recurrentes
Para la cadena de markov definida se obtiene que:
recurrentClasses(mc)## [[1]]
## [1] "a" "b" "c"recurrentClasses(mc)## [[1]]
## [1] "a" "b" "c"transientStates(mc)## character(0)absorbingStates(mc)## character(0)3.13 Análisis Probabilístico
Para conocer la probabilidad de transición en 1 paso entre un estado y otro basta con utilizar la función transitionProbability(), con los argumentos:
object: la cadena de markov
t0: el estado en el tiempo 0
t1: el estado en el tiempo 1
La probabilidad de transicion en un paso del estado “a” al estado “c” es:
transitionProbability(object = mc,t0 = "a",t1 = "c")## [1] 0.5Recuerde que dicha probabilidad es un elemento de la matriz de transición P, por lo tanto, la probabilidad de transicion del estado “a” al estado “b” es simplemente P23
mc[2,3]## [1] 0.5Es posible computar la matriz de transición en n pasos, simplemente computando la n-ésima potencia de la matriz de transición P, como ejemplo calcularemos la matriz de transición en n = 5 pasos.
n = 5 # El número de pasos al futuro mc ^ n
n = 5 # El número de pasos al futuro
mc ^ n## Cadena 1^5
## A 3 - dimensional discrete Markov Chain defined by the following states:
## a, b, c
## The transition matrix (by rows) is defined as follows:
## a b c
## a 0.31250 0.34375 0.34375
## b 0.34375 0.31250 0.34375
## c 0.34375 0.34375 0.31250Tambien se pueden conocer la distribución de la cadena en n pasos adelante (P(Xn)) multiplicando la distribucion inicial de X0 por la matriz de transición en n pasos (Pn), calcule la distribución de la cadena en el tiempo n = 6, si la ditribución inicial de la cadena es “(0.5, 0.2, 0.3)”.
X0 = c(0.5,0.2,0.3) # La distribucion de X en t = 0
n = 6
Xn = X0*(mc^n)
Xn## a b c
## [1,] 0.3359375 0.33125 0.3328125Por lo tanto la distribución de la cadena en 6 pasos es:
Puesto que Xn es una función de densidad, la suma de las probabilidades en todos los estados debe ser 1.
sum(Xn)## [1] 1Finalmente encontrar la distribución estacionaria de la cadena se obtiene mediante la función “steadyStates” de la siguiente forma:
DistEst = steadyStates(mc)
DistEst## a b c
## [1,] 0.3333333 0.3333333 0.3333333Recuerde que los tiempos medio de recurrencia son los inversos multiplicativos de la distribución estacionaria y pueden ser computados facilmente.
M = 1/DistEst
M## a b c
## [1,] 3 3 33.14 Ejercicio Markov
Dibuje el diagrama de transición, determine las clases de comunicación de las siguientes cadenas de Markov, clasifique éstas como recurrentes o transitorias , y encuentre la distribución estacionaria si existe .
\[P=⎛⎝⎜⎜⎜⎜1/2001/41/21/21/21/401/21/21/40001/4⎞⎠⎟⎟⎟⎟\]
| Estado | Compra en el siguiente mes | TOTALES |
|---|---|---|
| Compra actual | Marca A | Marca B | Marca C | Total |
|---|---|---|---|---|
| Marca A = 1690 | 507 | 845 | 338 | 1690 |
| Marca B = 3380 | 676 | 2028 | 676 | 3380 |
| Marca C = 3380 | 845 | 845 | 1690 | 3380 |
| TOTALES | 2028 | 3718 | 2704 | 8450 |
Para resolver este problema del segundo examen basta con almacenar correctamente la matriz de transición y usar los comandos presentados.
Q = matrix(data = c(0.5,0.5,0,0,0,0.5,0.5,0,0,0.5,0.5,0,0.25,0.25,0.25,0.25),nrow = 4,byrow = TRUE)
Q## [,1] [,2] [,3] [,4]
## [1,] 0.50 0.50 0.00 0.00
## [2,] 0.00 0.50 0.50 0.00
## [3,] 0.00 0.50 0.50 0.00
## [4,] 0.25 0.25 0.25 0.25Por lo tanto la cadena de markov clasificada es:
Ejer1 = new("markovchain",transitionMatrix = Q,states = c("0","1","2","3"))
summary(Ejer1)## Unnamed Markov chain Markov chain that is composed by:
## Closed classes:
## 1 2
## Recurrent classes:
## {1,2}
## Transient classes:
## {0},{3}
## The Markov chain is not irreducible
## The absorbing states are: NONEplot(Ejer1)
Y la distribución estacionaria de la matríz es:
steadyStates(Ejer1)## 0 1 2 3
## [1,] 0 0.5 0.5 0##Aplicaciones
En aplicaciones cotidianas la matriz de transición P es desconocida, usualmente la información conocida es un registro en el tiempo del comportamiento de algún fenómeno, y por lo tanto es necesario estimar la matriz de transición para los registros dados, (Inferencia y Estadistica 2).
Como ejemplo se presenta el registro semanal del número de veces que llueve en alguna ciudad desconocida, almacenados en la base de datos rain. Cargando y revisando los archivos:
data(rain)
str(rain)## 'data.frame': 1096 obs. of 2 variables:
## $ V1 : int 3 2 2 2 2 2 2 3 3 3 ...
## $ rain: chr "6+" "1-5" "1-5" "1-5" ...La variable rain de los datos guarda el registro del número de veces que llueve de la forma, la tabla de frecuencias para rain es:
table(rain$rain)##
## 0 1-5 6+
## 548 295 253Podemos observar los primeros registros de los datos de la siguiente forma:
head(rain)## V1 rain
## 1 3 6+
## 2 2 1-5
## 3 2 1-5
## 4 2 1-5
## 5 2 1-5
## 6 2 1-5Como modelo se propone una cadena de markov finita de 3 estados para modelar los registros semanales del numero de veces que llueve almacenados en rain.
PE = rain$rain
head(PE)## [1] "6+" "1-5" "1-5" "1-5" "1-5" "1-5"La libreria markovchain, nos provee herramientas para estimar la matriz de transicion de la cadena mediante los datos obtenidos. La función “CreateSequenceMatrix()” crea una matriz de secuencia
P1 = createSequenceMatrix(PE)
P1## 0 1-5 6+
## 0 362 126 60
## 1-5 136 90 68
## 6+ 50 79 124Donde cada elemento \(p_{ij}\) de la matriz representa el número de veces que el proceso paso del estado i al estado j. La funcion markovchainFit() estima la matriz de transición para el registro de datos, utilizando el metodo de maxima verosimilitud (MLE).
Fit = markovchainFit(data = PE,confidencelevel = 0.95)
Fit## $estimate
## MLE Fit
## A 3 - dimensional discrete Markov Chain defined by the following states:
## 0, 1-5, 6+
## The transition matrix (by rows) is defined as follows:
## 0 1-5 6+
## 0 0.6605839 0.2299270 0.1094891
## 1-5 0.4625850 0.3061224 0.2312925
## 6+ 0.1976285 0.3122530 0.4901186
##
##
## $standardError
## 0 1-5 6+
## 0 0.03471952 0.02048353 0.01413498
## 1-5 0.03966634 0.03226814 0.02804834
## 6+ 0.02794888 0.03513120 0.04401395
##
## $confidenceLevel
## [1] 0.95
##
## $lowerEndpointMatrix
## 0 1-5 6+
## 0 0.5925349 0.1897800 0.0817850
## 1-5 0.3848404 0.2428780 0.1763188
## 6+ 0.1428496 0.2433971 0.4038528
##
## $upperEndpointMatrix
## 0 1-5 6+
## 0 0.7286330 0.2700740 0.1371931
## 1-5 0.5403296 0.3693669 0.2862663
## 6+ 0.2524073 0.3811089 0.5763843
##
## $logLikelihood
## [1] -1040.419Dicha función devuelve una lista con todos los resultados de la estimaciones, incluyendo un objeto markovchain que posee la matriz de transición. Para el ejemplo anterior se tienen los siguientes resultados.
mc = Fit$estimate
summary(mc)## MLE Fit Markov chain that is composed by:
## Closed classes:
## 0 1-5 6+
## Recurrent classes:
## {0,1-5,6+}
## Transient classes:
## NONE
## The Markov chain is irreducible
## The absorbing states are: NONEEl diagrama de transición de la cadena es:
plot(mc)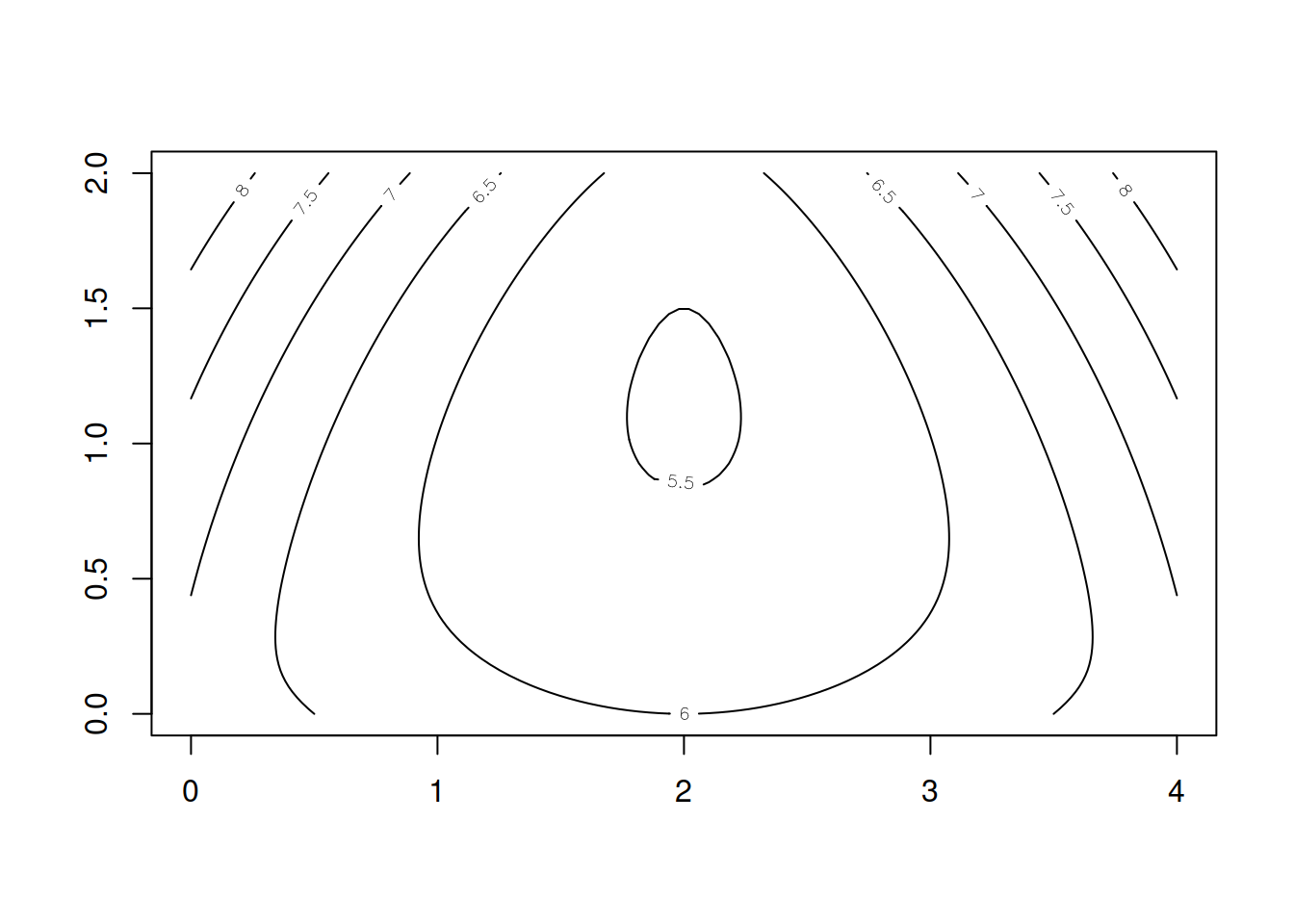
Y la distribución estacionaria de la matriz es:
steadyStates(mc)## 0 1-5 6+
## [1,] 0.5008871 0.2693656 0.22974733.15 Predicciones
Una de las utilidades mas grandes de los Procesos Estocásticos, es su capacidad de realizar predicciones, esto se puede realizar mediante la función “predict()”, para eso observemos los ultimos registros del proceso
tail(PE)## [1] "0" "1-5" "0" "6+" "6+" "1-5"Se observa que la última semana llovió entre 1 y 5 veces, como el modelo es una cadena de markov, para realizar una predicción de la siguiente semana, necesita conocer la semana actual, las prediciones para las siguientes* n = 3* semanas dado que en la utlima vez se registraron entre 1 y 5 lluvias, son:
predict(mc,newdata = "1-5",n.ahead = 3)## [1] "0" "0" "0"Para mayor información de la funcionalidad del paquete o mayor conocimiento de otras funciones pueden revisar el artículo de Giorgio Alfredo, Tae Seung y otros llamado “The markovchain Package: A Package for Easily Handling Discrete Markov Chains in R” mediante el siguiente Enlace
3.16 Ejercicio G1:
Sean los puntos:
\[ A = (59.5 , 71.87) \] \[ B = (135.09 , 113.98) \] \[ C = (114.31, 62,03)\]
1- Trazar un polígono con los tres puntos. 2- Replique el segmento \(AC\) a partir del punto \(B\) 3- Replique el segmento \(CB\) a partir del punto \(A\) 4- Identifique el punto \(G\) en que ambos segmentos construidos se interceptan 5- Trace la recta \(GC\)
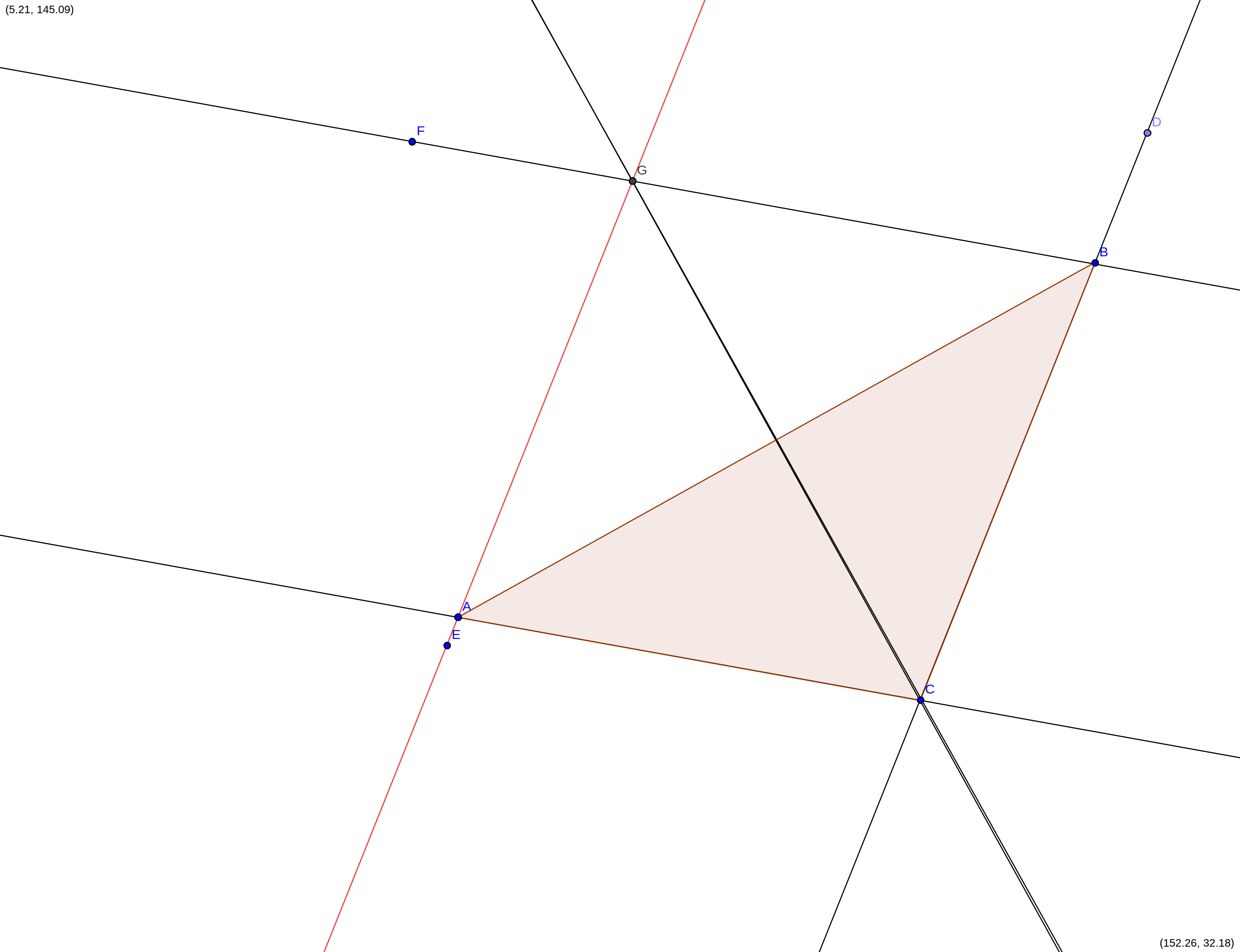 6- ¿Existe perpendicularidad entre entre AB y CG?
6- ¿Existe perpendicularidad entre entre AB y CG?
Link para descargar el ejercicio ejercicio 1
3.17 Propuesta geometrica de Fermat
La propuesta de localización de almacenes de Fermat puede ser interpretada geométricamente de un modo más sencillo que el empleado en su formulación matemática.
Desarrollaremos una serie de ejercicios geométricos para entender como concebía la solución Fermat. Te recomendamos que realices los siguientes ejercicios con papel y escuadra, o en su defecto que utilices alguna herramienta como geogebra (que es la que se utiliza en este ejemplo).
3.17.1 Ejercicio G2
Utilizaremos el primer método de localización propuesto para tres punto que tienen igual consumo. La idea es construir en cada lado del triángulo que determina los puntos A,B,C un triángulo equilátero y unir este vértice con la mediatriz de cada segmente \(\overline{\rm AB} , \overline{\rm BC}, \overline{\rm CA}\).
 Observa que está presente el tríángulo color rosa del ejercicio anterior.
Observa que está presente el tríángulo color rosa del ejercicio anterior.
Link para descargar el ejercicio ejercicio 2
3.17.2 Ejercicio G3
¿Donde existe un espacio de soluciones posibles, tal que considerando el paralelogramo y el triángulo construido sean lugares geométricos que minimicen la distancia a los puntos \(A, B, C\)? La solución es encontrar una circunferencia que pase por los tres puntos y que divida al espacio en dos semicircunferencias iguales (conceptos de espacio vectorial de equidistancia). Esa línea que divide al circulo en dos mitades iguales tiene que ser necesariamente un radio. Se puede ver en la figura que pasa por el vértice del triángulo equilátero amarillo y el paralelogramo de Fermat.
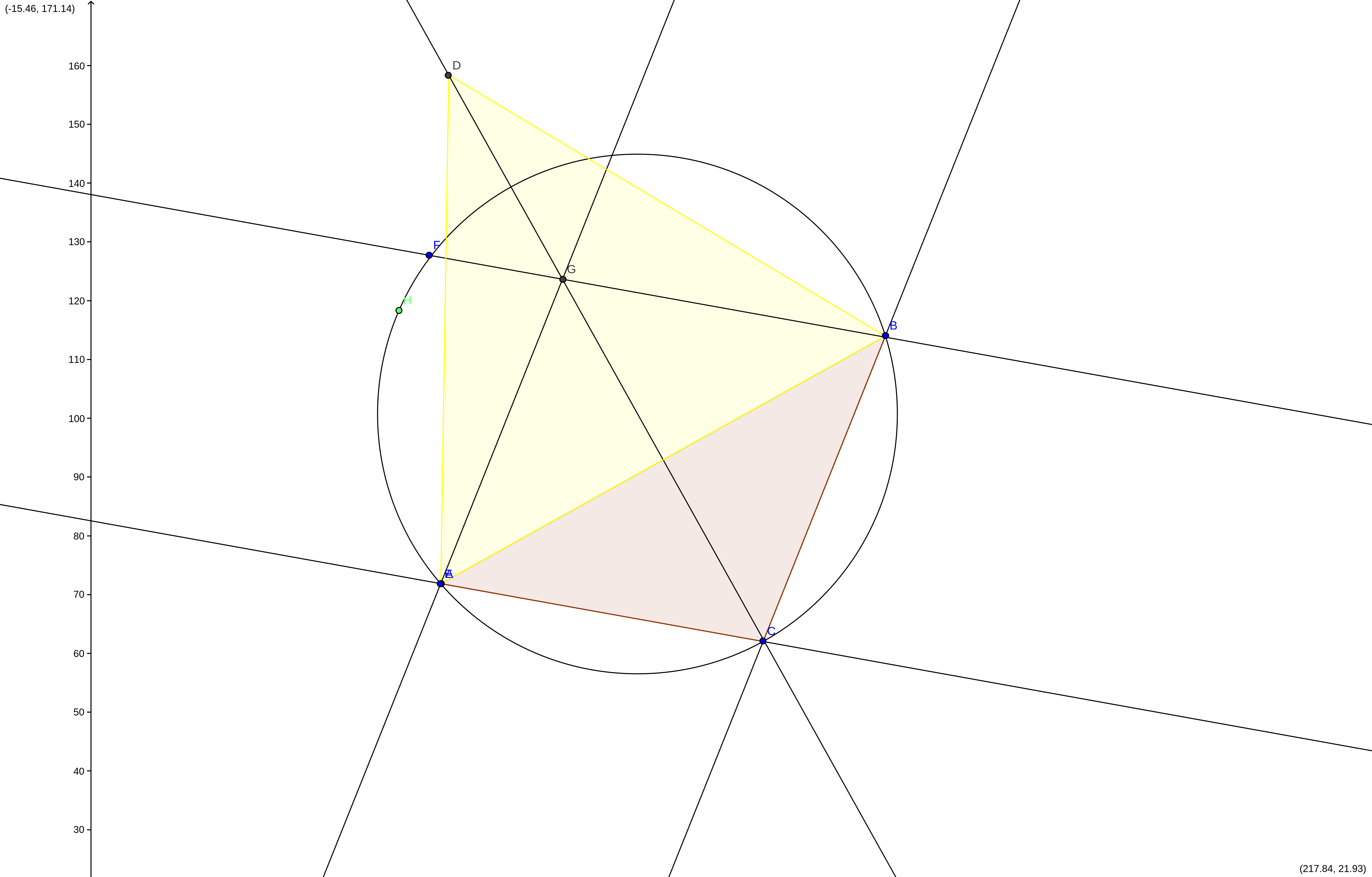
Triangulacion Fermat
Link para descargar el ejercicio ejercicio 3
Si repetimos este procedimiento para construir las tres circunferencias con los tres triángulos equiláteros tendríamos un punto en el que coinciden los tres diámetros que se cruzan en el punto que es espacio vectorial de soluciones y es el único punto de equidista de los tres vértices que representan las localizaciones de las demandas. El punto donde se cruzan los tres diámetros debería ser el puto en el que se instala la manufactura.
Esta es la estrategia del método del baricentro que se utiliza para fijar la localización.
3.17.3 Ejercicio G4 (no lo quiero en mi patio)
La primer aproximación que Fermat intenta es la de dar respuesta a la localización por atracción. Es decir consumidores que están en los puntos \(A, B, C\) y desean minimizar su costo de transporte. Pero, ¿que ocurre si en logar de atracción pensamos en repulsión?. ¿Cómo cambia este esquema si en lugar de planear la localización de un hospital, o un supermercado, estoy localizando un vertedero de residuos patológicos?
El esquema propuesto por Fermat es el siguiente. Está basado en una solución de la ortogonalida de los catetos.

Ortogonalidad de Catetos
Link para descargar el ejercicio ejercicio 4
3.17.4 Ejercicio G6
Este ejercicio es el primer método de Fermat denominado “Método del Centro Isogónico” propuesto por Fermat para la localización de un centro que abastezca a tres centro de consumo. Consiste en tomar los tres lados del triángulo determinado por los centros de consumo, y construir sobre cada lado sendos triángulos equiláteros. Evalgelista Torricelli demostró que este método otorga un punto cuya suma de distancia a los tres centros de consumos es MÍNIMA solamente si no existe un ángulo del triángulo que sea mayor a 120°.
Esta importante consecuencia del punto de Fermat es la prueba que indica que el resultado del método del baricentro (el más utilizado en el mundo) puede estar dando errores que desconocemos.
Ejemplo del método del centro Isogónico
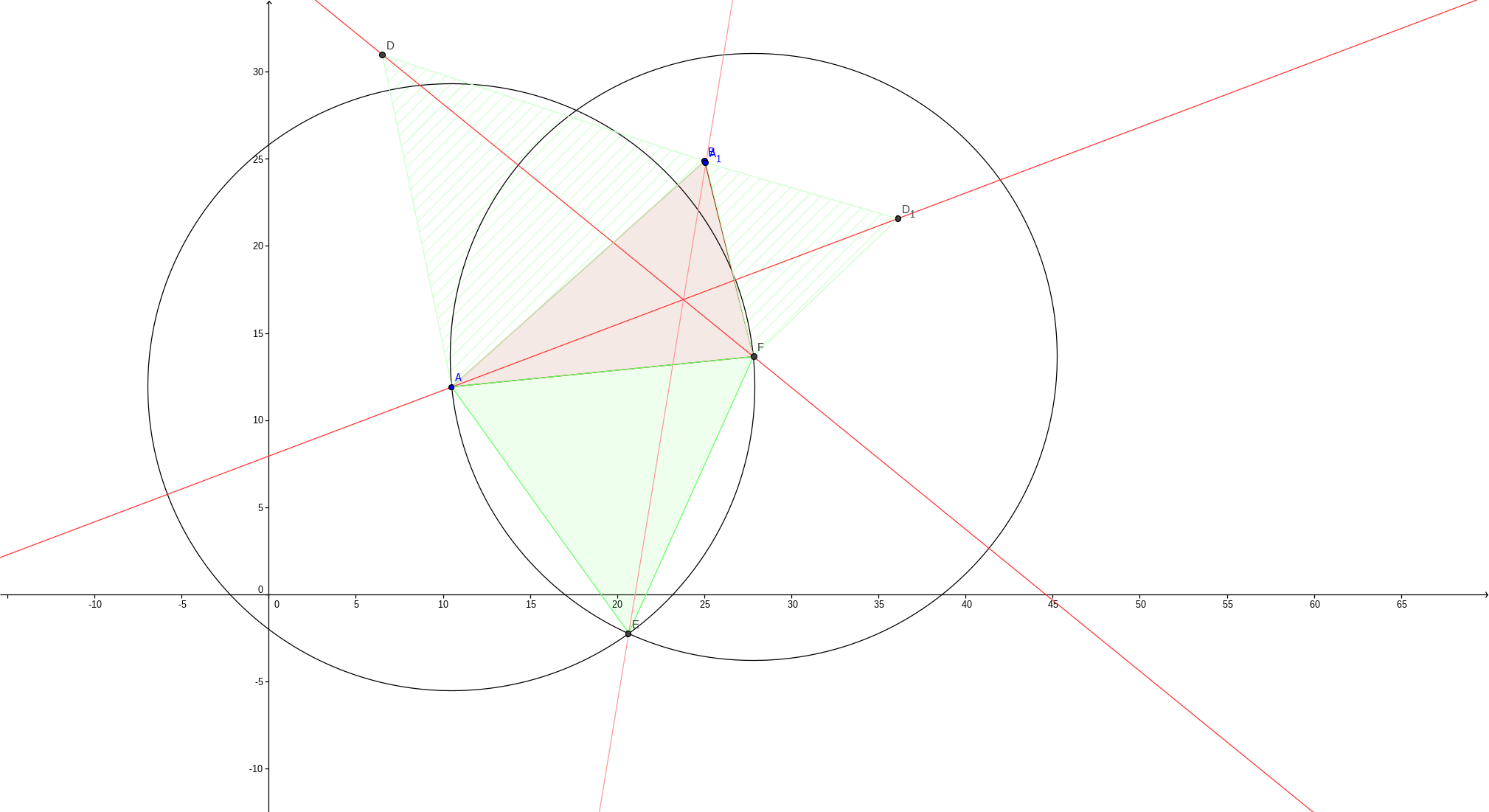
El método isogónico
Link para descargar el ejercicio ejercicio 8
3.17.5 Ejercicio G7
Ejemplo del método de Fermat de tríangulos equláteros cuando no se desea tener cerca el centro de abastecimiento.
Ejemplo del método del centro Isogónico repulsivo
El método isogónico
Link para descargar el ejercicio ejercicio 9
3.17.6 Ejercicio G8
Sean Los puntos:
\[ A (-32.92713427858885, -68.81772766801757)\] \[ B (-32.86788086975811, -68.85428072392608) \]
Determinar :
- La Distancia Euclídea
- La Distancia Manhatam
- Representación geomática
- ¿Que ruta elegirías para llegar desde A hasta B?
Solución:
Distancia Euclídea
A <- c(-32.92713427858885, -68.81772766801757)
B <- c(-32.86788086975811, -68.85428072392608)
Dy2 <- (A[1]-B[1])^2
Dx2 <- (A[2]-B[2])^2
D_g <- sqrt(Dy2 + Dx2)
D_g## [1] 0.06962106Sabemos que 1° de latitud o longitud equivalen sobre el geoide a 111.11 Km por lo tanto la distancia en Km de este arco será:
D_km <- 111.11 *D_g /1
D_km## [1] 7.735596Distancia Manhatam
Dy <- (A[1]-B[1])
Dx <- (A[2]-B[2])
D_h <- abs(Dx) + abs(Dy)
D_h## [1] 0.09580646D_h <- 111.11 * D_h
D_h## [1] 10.64506Representación Geomática
Cluster de Puntos
library(leaflet)
library(leaflet.extras)
library(tidyverse)## ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.1 ──## ✓ ggplot2 3.3.5 ✓ purrr 0.3.4
## ✓ tibble 3.0.4 ✓ dplyr 1.0.7
## ✓ tidyr 1.1.4 ✓ stringr 1.4.0
## ✓ readr 1.4.0 ✓ forcats 0.5.1## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()consumo <- c(-32.91682953269615, -68.76609482656337, -200, -20, -32.92721825526954, -68.81768957684899,3 , 1 , -32.911401355733354, -68.82484400346665 , 5 ,4, -32.89442568503209, -68.83059940148742, 1,6, -32.892425579377154, -68.83308860323564 ,5 ,2, -32.896226807794974, -68.82193031473983 ,2,8 , -32.89855141165897, -68.80510778757831 ,4 , 4, -32.867593934431554, -68.85439436934425 ,3,2 , -32.872045010628426, -68.86456858203749 ,3,8 , -32.91498350785812, -68.84497345198642 ,1,5 , -32.92790119153266, -68.85940216631148 ,5,8 , -32.89427179600652, -68.7997089938368 ,2 ,4 )
consumo_matrix <- matrix(consumo,ncol=4, byrow = TRUE)
colnames(consumo_matrix) <- c("Lat","Lng","Pallets","Semanas")
consumo_matrix## Lat Lng Pallets Semanas
## [1,] -32.91683 -68.76609 -200 -20
## [2,] -32.92722 -68.81769 3 1
## [3,] -32.91140 -68.82484 5 4
## [4,] -32.89443 -68.83060 1 6
## [5,] -32.89243 -68.83309 5 2
## [6,] -32.89623 -68.82193 2 8
## [7,] -32.89855 -68.80511 4 4
## [8,] -32.86759 -68.85439 3 2
## [9,] -32.87205 -68.86457 3 8
## [10,] -32.91498 -68.84497 1 5
## [11,] -32.92790 -68.85940 5 8
## [12,] -32.89427 -68.79971 2 4mision <- data.frame(lat=consumo_matrix[ ,1], long=consumo_matrix[ ,2], pallets=consumo_matrix[ ,3],semanas=consumo_matrix[ ,4],stringsAsFactors=FALSE)
leaflet(data = mision) %>% addTiles() %>% addMarkers(clusterOptions = markerClusterOptions())## Assuming "long" and "lat" are longitude and latitude, respectivelyPuedes importar los datos desde este link.
https://themys.sid.uncu.edu.ar/rpalma/R-cran/Hospitales_Consumo.csv"
** Mapa interactivo** Puedo consultar el consumo de pallets y cada cuantas semanas me llaman para abastecerlos
leaflet(data = mision) %>% addTiles() %>% addMarkers(~long, ~lat, popup = ~as.character(pallets), label = ~as.character(semanas))3.18 Revisión bibliográfica de distancias
| Developed year | Problem | Distance | Developer | References |
|---|---|---|---|---|
| 1909 | Continues location problem | Euclidean distances | Weber | Hamacher and Nickel (1998) |
| 1937 | Multi facility | Euclidean | Weiszfeld Munoz-Perez and Saameno- Rodrõguez (1999) | |
| 1963 | Multifacility location problem Rectilinear distances in a network of aisles | Francis | Munoz-Perez and Saameno- Rodrõguez (1999) | |
| 1970 | Private and public sector location models | Lp distance | ReVelle et al. Munoz-Perez and Saameno- Rodrõguez (1999) | |
| 1973 | Multifacility location problem | Euclidean & rectilinear distances (HAP procedure) | Eyster et al. | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1977 | Traveling salesman location problem | Rectilinear distances | Chan, Hearn | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1978 | Fixed charge plant location problem (using LP) | Random and euclidean distances | Morris | Schilling et al. (2000) |
| 1980 | Unweighted 1-maximin problem in a bounded & convex polyhedron in Rk | Euclidean distances | Dasarathy, White | Chae and Fromm (2005) |
| 1980 | Weighted 1 maximin problem | Euclidean distances | Drezner, Wesolowsky | Chae and Fromm (2005) |
| 1981 | Generalized versions of 1-maximin models | Euclidean distances | Hansen et al. | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1981 | Location problem with barriers for median problem | Euclidean distances Katz, Cooper | Plastria and Carrizosa (2004) | |
| 1982 | Traveling salesman location problem | Rectilinear, euclidean, and Lp distance problems | Drezner, Wesolowsky | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1983 | Location problem with barriers for median problem | Rectilinear distances Larson, Sadiq | Plastria and Carrizosa (2004) | |
| 1986 | Location of an undesirable facility Weighted | inverse square distance Melachrinoudis, Cullinane | Munoz-Perez and Saameno- Rodrõguez (1999) | |
| 1986 | Location of an undesirable facility | Euclidean & rectilinear distances Melachrinoudis, Cullinane | Munoz-Perez and Saameno- Rodrõguez (1999) | |
| 1986 | Single facility location problem | Minimizing the variance of distances Maimon | Chung et al. (2007) | |
| 1987 | The median shortest path problem | Shortest path distance | Current et al. Hamacher and Nickel (1998) | |
| 1989 | Assigning machines to locations | Distance matrix Sarker | Yu and Sarker (2003) | |
| 1992 | Improved traveling salesman location problem | Rectilinear distances | Tamir | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1994 | Weber facility location in the presence of forbidden regions | Lp distance Aneja, Palar | Hamacher and Nickel (1998) | |
| 1994 | Competitive location model | Euclidean distances | T. Drezner | Plastria and Carrizosa (2004) |
| 1995 | Undesirable facility location by generalized cutting planes | Euclidean distances | Carrizosa, Plastria | Hamacher and Nickel (1998) |
| 1995 | Bi objective min quantile max covering problems | Euclidean distances | Carrizosa, Plastria | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1996 | Locating a point in a network | Shortest path distance | Drezner, Wesolowsky | Munoz-Perez and Saameno- Rodrõguez (1999) |
| 1996 | Location problem with barriers for median problem | Euclidean distances | Butt, Cavalier | Plastria and Carrizosa (2004) |
| 1997 | P-Median problem (new heuristic approach) | Euclidean distances | Dai, Cheung | Hamacher and Nickel (1998) |
| 1998 | Locating a new facility in a competitive environment | Euclidean distances with correction | Drezner T, Drezner Z | Drezner and Drezner (1998) |
| 1999 | A P-center grid positioning | Rectilinear distances | Rayco et al. | Hamacher and Nickel (1998) |
| 2000 | Designing distribution systems | Rectilinear distances | Erlebacher, Meller | Hamacher and Nickel (1998) |
| 2000 | Location problem with barriers for median problem | Lp distance | Hamacher, Klamroth | Hamacher and Nickel (1998) |
| 2001 | The K-centrum multi facility location problem | K largest distances in a graph Tamir | Hamacher and Nickel (1998) | |
| 2002 | Location problem with barriers for center problem | Rectilinear distances | Dearing et al. | Dearing et al. (2005) |
| 2008 | Quadratic assignment problem | Number of variables with different values in the population members (Ga) | Drezner Z | Drezner (2008) |